Examples of including covariates with bayesdfa
Eric J. Ward, Sean C. Anderson, Mary E. Hunsicker, Mike A. Litzow, Luis A. Damiano, Mark D. Scheuerell, Elizabeth E. Holmes, Nick Tolimieri
2026-05-26
Source:vignettes/a3_covariates.Rmd
a3_covariates.RmdHere we will walk through how to use the bayesdfa package to fit dynamic factor analysis (DFA) models with covariates.
Let’s load the necessary packages:
Notation review for DFA models
Covariates in dynamic factor analysis are generally included in the observation model, rather than the process model. Without covariates, the model can be expressed as
$${x}_{t}={x}_{t-1}+{e}_t\\ { e }_{ t }\sim MVN(0,\textbf{Q})\\ { y }_{ t }=\textbf{Z}{ x }_{ t }+{ v }_{ t }\\ { v }_{ t }\sim MVN(0,\textbf{R})$$
where the matrix is dimensioned as the number of time series by number of trends, and maps the observed data to the latent trends .
Observation covariates
Observation covariates can be $${x}_{t}={x}_{t-1}+{e}_t\\ { e }_{ t }\sim MVN(0,\textbf{Q})\\ { y }_{ t }=\textbf{Z}{ x }_{ t }+\textbf{D}{ d }_{ t }+{ v }_{ t }\\ { v }_{ t }\sim MVN(0,\textbf{R})$$ where the matrix represents time series by number of covariates at time . For a single covariate, such as temperature, this would mean estimating parameters, where is the number of time series. For a model including 2 covariates, the number of estimated coefficients would be and so forth.
Process covariates
Process covariates on the trends are less common but can be written as $${x}_{t}={x}_{t-1}+\textbf{C}{ c }_{ t }+{e}_t\\ { e }_{ t }\sim MVN(0,\textbf{Q})\\ { y }_{ t }=\textbf{Z}{ x }_{ t }+{ v }_{ t }\\ { v }_{ t }\sim MVN(0,\textbf{R})$$ where the matrix represents the number of trends by number of covariates at time . For a single trend, this would mean estimating parameters, where is the number of trends. For a model including 2 covariates, the number of estimated coefficients would be and so forth.
Examples – observation covariates
We’ll start by simulating some random trends using the
sim_dat function,
Next, we can add a covariate effect to the trend estimate,
x. For example,
cov = expand.grid("time"=1:20, "timeseries"=1:4, "covariate"=1)
cov$value = rnorm(nrow(cov),0,0.1)
for(i in 1:nrow(cov)) {
sim_dat$y[cov$timeseries[i],cov$time[i]] = sim_dat$pred[cov$timeseries[i],cov$time[i]] +
c(0.1,0.2,0.3,0.4)[cov$timeseries[i]]*cov$value[i]
}And now fit the model with fit_dfa
mod = fit_dfa(y = sim_dat$y, obs_covar = cov, num_trends = 1,
chains=chains, iter=iter)We can then make plots of the true and estimated trend,
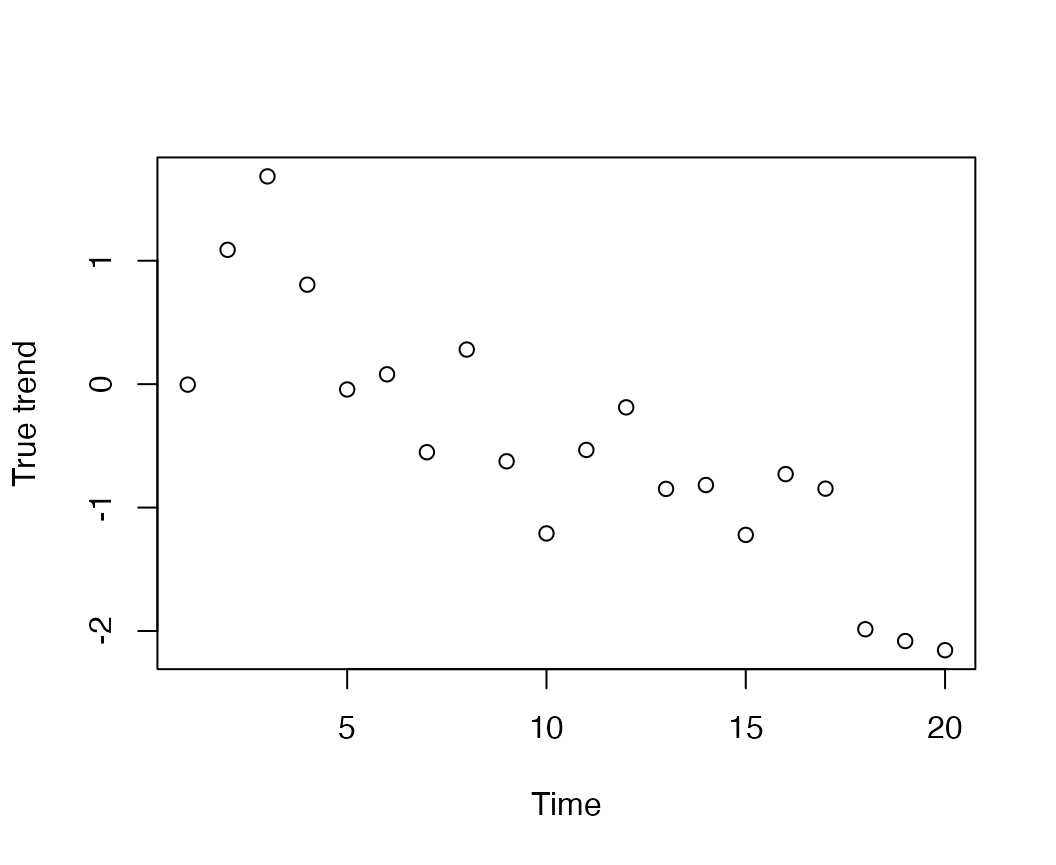
plot_trends(rotate_trends(mod)) + ylab("Estimated trend") + theme_bw()## Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
## ℹ Please use tidy evaluation idioms with `aes()`.
## ℹ See also `vignette("ggplot2-in-packages")` for more information.
## ℹ The deprecated feature was likely used in the bayesdfa package.
## Please report the issue at <https://github.com/fate-ewi/bayesdfa/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.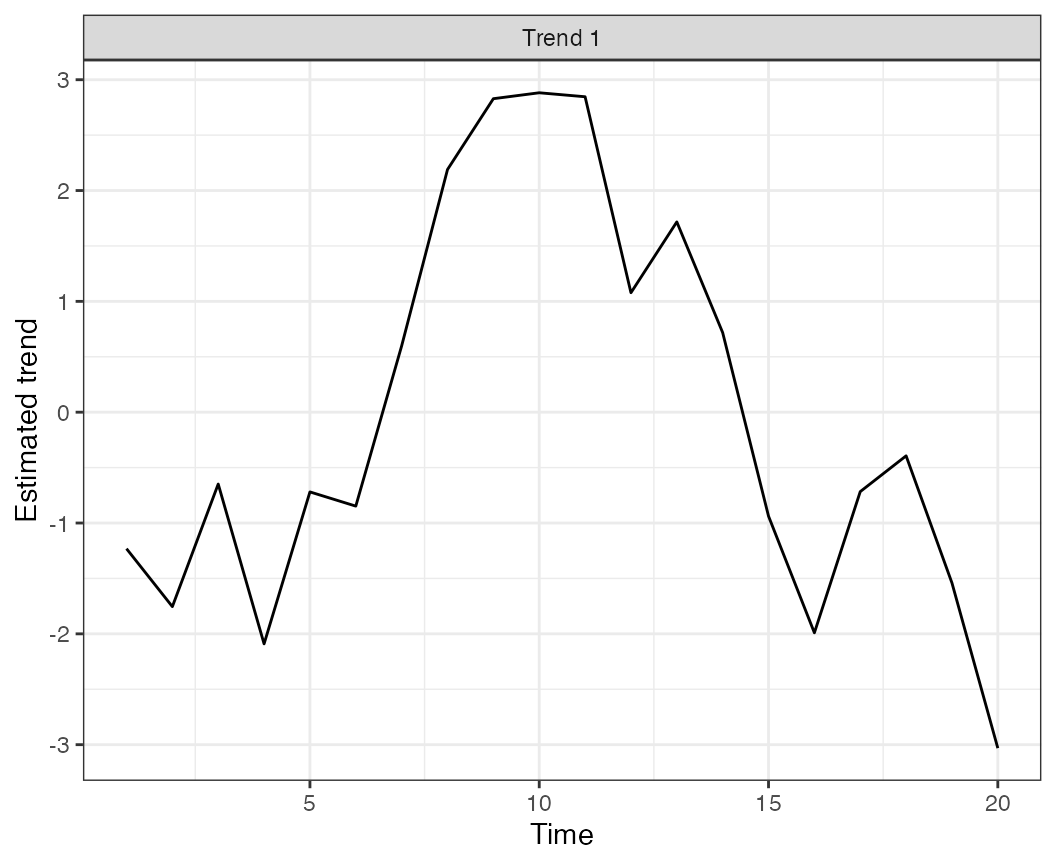
This approach could be modified to have covariates not affecting some time series. For example, if we didn’t want the covariate to affect the last time series, we could say
cov = cov[which(cov$timeseries!=4),]And then again fit the model
mod = fit_dfa(y = sim_dat$y, obs_covar = cov, num_trends = trends,
chains=chains)Examples – process covariates
As a cautionary note, there’s some identifiability issues with including covariates in the process model. Covariates need to be standardized or centered prior to being included. Future versions of this vignette will include more clear examples and recommendations.
We’ll start by simulating some random trends using the
sim_dat function,
Next, we can add a covariate effect to the trend estimate,
x. For example,
cov = rnorm(20, 0, 1)
b_pro = c(1,0.3)
x = matrix(0,2,20)
for(i in 1:2) {
x[i,1] = cov[1]*b_pro[i]
}
for(i in 2:length(cov)) {
x[1,i] = x[1,i-1] + cov[i]*b_pro[1] + rnorm(1,0,1)
x[2,i] = x[2,i-1] + cov[i]*b_pro[2] + rnorm(1,0,1)
}
y = sim_dat$Z %*% xAnd now fit the model with fit_dfa
pro_cov = expand.grid("trend"=1:2, "time"=1:20, "covariate"=1)
pro_cov$value = cov[pro_cov$time]
mod = fit_dfa(y = sim_dat$y, pro_covar = pro_cov, num_trends = 2,
chains=chains, iter=iter)