Plot the fitted values from a DFA
plot_fitted(
modelfit,
conf_level = 0.95,
names = NULL,
spaghetti = FALSE,
time_labels = NULL
)Arguments
- modelfit
Output from
fit_dfa, a rstanfit object- conf_level
Probability level for CI.
- names
Optional vector of names for plotting labels TODO. Should be same length as the number of time series
- spaghetti
Defaults to FALSE, but if TRUE puts all raw time series (grey) and fitted values on a single plot
- time_labels
Optional vector of time labels for plotting, same length as number of time steps
See also
plot_loadings fit_dfa rotate_trends dfa_fitted
Examples
# \donttest{
y <- sim_dfa(num_trends = 2, num_years = 20, num_ts = 4)
m <- fit_dfa(y = y$y_sim, num_trends = 2, iter = 50, chains = 1)
#>
#> SAMPLING FOR MODEL 'dfa' NOW (CHAIN 1).
#> Chain 1:
#> Chain 1: Gradient evaluation took 2.3e-05 seconds
#> Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 0.23 seconds.
#> Chain 1: Adjust your expectations accordingly!
#> Chain 1:
#> Chain 1:
#> Chain 1: WARNING: There aren't enough warmup iterations to fit the
#> Chain 1: three stages of adaptation as currently configured.
#> Chain 1: Reducing each adaptation stage to 15%/75%/10% of
#> Chain 1: the given number of warmup iterations:
#> Chain 1: init_buffer = 3
#> Chain 1: adapt_window = 20
#> Chain 1: term_buffer = 2
#> Chain 1:
#> Chain 1: Iteration: 1 / 50 [ 2%] (Warmup)
#> Chain 1: Iteration: 5 / 50 [ 10%] (Warmup)
#> Chain 1: Iteration: 10 / 50 [ 20%] (Warmup)
#> Chain 1: Iteration: 15 / 50 [ 30%] (Warmup)
#> Chain 1: Iteration: 20 / 50 [ 40%] (Warmup)
#> Chain 1: Iteration: 25 / 50 [ 50%] (Warmup)
#> Chain 1: Iteration: 26 / 50 [ 52%] (Sampling)
#> Chain 1: Iteration: 30 / 50 [ 60%] (Sampling)
#> Chain 1: Iteration: 35 / 50 [ 70%] (Sampling)
#> Chain 1: Iteration: 40 / 50 [ 80%] (Sampling)
#> Chain 1: Iteration: 45 / 50 [ 90%] (Sampling)
#> Chain 1: Iteration: 50 / 50 [100%] (Sampling)
#> Chain 1:
#> Chain 1: Elapsed Time: 0.003 seconds (Warm-up)
#> Chain 1: 0.008 seconds (Sampling)
#> Chain 1: 0.011 seconds (Total)
#> Chain 1:
#> Warning: There were 19 divergent transitions after warmup. See
#> https://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
#> to find out why this is a problem and how to eliminate them.
#> Warning: There were 1 chains where the estimated Bayesian Fraction of Missing Information was low. See
#> https://mc-stan.org/misc/warnings.html#bfmi-low
#> Warning: Examine the pairs() plot to diagnose sampling problems
#> Warning: The largest R-hat is NA, indicating chains have not mixed.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#r-hat
#> Warning: Bulk Effective Samples Size (ESS) is too low, indicating posterior means and medians may be unreliable.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#bulk-ess
#> Warning: Tail Effective Samples Size (ESS) is too low, indicating posterior variances and tail quantiles may be unreliable.
#> Running the chains for more iterations may help. See
#> https://mc-stan.org/misc/warnings.html#tail-ess
#> Inference for the input samples (1 chains: each with iter = 25; warmup = 12):
#>
#> Q5 Q50 Q95 Mean SD Rhat Bulk_ESS Tail_ESS
#> x[1,1] -0.6 -0.6 -0.6 -0.6 0.0 1.03 13 13
#> x[2,1] 0.4 0.4 0.4 0.4 0.0 1.16 9 13
#> x[1,2] 1.0 1.0 1.0 1.0 0.0 1.16 9 13
#> x[2,2] -0.7 -0.6 -0.6 -0.6 0.0 1.11 8 13
#> x[1,3] 1.7 1.7 1.7 1.7 0.0 2.16 3 6
#> x[2,3] -0.2 -0.1 -0.1 -0.1 0.0 1.16 7 13
#> x[1,4] 1.6 1.6 1.6 1.6 0.0 2.16 3 6
#> x[2,4] -0.4 -0.4 -0.4 -0.4 0.0 0.99 9 13
#> x[1,5] 2.8 2.8 2.8 2.8 0.0 2.16 3 6
#> x[2,5] -1.0 -1.0 -1.0 -1.0 0.0 1.16 10 13
#> x[1,6] 1.0 1.1 1.1 1.1 0.0 2.16 3 6
#> x[2,6] -1.6 -1.6 -1.6 -1.6 0.0 2.23 9 13
#> x[1,7] 2.0 2.1 2.1 2.1 0.0 2.16 3 6
#> x[2,7] -0.6 -0.6 -0.6 -0.6 0.0 1.63 10 13
#> x[1,8] 1.9 1.9 1.9 1.9 0.0 2.16 3 6
#> x[2,8] 0.3 0.3 0.3 0.3 0.0 1.63 10 13
#> x[1,9] 2.4 2.5 2.5 2.5 0.0 2.16 3 6
#> x[2,9] -1.3 -1.3 -1.3 -1.3 0.0 2.22 9 13
#> x[1,10] 2.9 2.9 2.9 2.9 0.0 2.16 3 6
#> x[2,10] -0.3 -0.3 -0.2 -0.3 0.0 1.63 9 13
#> x[1,11] 2.3 2.4 2.4 2.4 0.0 2.16 3 6
#> x[2,11] -0.9 -0.9 -0.8 -0.9 0.0 2.22 9 13
#> x[1,12] 1.1 1.2 1.2 1.2 0.0 2.16 3 6
#> x[2,12] -0.7 -0.7 -0.6 -0.7 0.0 2.22 9 13
#> x[1,13] 2.1 2.2 2.2 2.2 0.0 2.16 3 6
#> x[2,13] 1.0 1.1 1.1 1.1 0.0 2.22 10 13
#> x[1,14] 3.2 3.3 3.3 3.3 0.0 2.16 3 6
#> x[2,14] -0.8 -0.8 -0.8 -0.8 0.0 1.63 10 13
#> x[1,15] 1.9 2.0 2.0 2.0 0.0 2.16 3 6
#> x[2,15] 0.9 1.0 1.0 1.0 0.0 2.22 9 13
#> x[1,16] 0.1 0.2 0.2 0.2 0.0 2.16 3 6
#> x[2,16] 2.1 2.1 2.1 2.1 0.0 1.63 13 13
#> x[1,17] -0.7 -0.6 -0.6 -0.6 0.0 2.16 3 6
#> x[2,17] 1.2 1.3 1.3 1.3 0.0 2.22 9 13
#> x[1,18] -0.9 -0.9 -0.8 -0.9 0.0 2.16 3 6
#> x[2,18] 0.4 0.4 0.4 0.4 0.0 1.14 12 13
#> x[1,19] 0.5 0.5 0.5 0.5 0.0 2.16 3 6
#> x[2,19] -0.7 -0.6 -0.6 -0.6 0.0 1.03 13 13
#> x[1,20] -0.5 -0.4 -0.4 -0.5 0.0 2.16 3 6
#> x[2,20] 0.8 0.8 0.8 0.8 0.0 1.21 12 13
#> Z[1,1] -0.3 -0.2 -0.1 -0.2 0.1 1.60 4 13
#> Z[2,1] 0.0 0.1 0.1 0.1 0.0 0.92 13 13
#> Z[3,1] -0.2 -0.1 0.2 -0.1 0.1 0.91 13 13
#> Z[4,1] -0.2 0.2 0.3 0.1 0.2 1.35 7 13
#> Z[1,2] 0.0 0.0 0.0 0.0 0.0 1.00 13 13
#> Z[2,2] 0.1 0.3 0.6 0.3 0.2 1.50 4 13
#> Z[3,2] 0.2 0.4 0.5 0.3 0.1 1.18 13 13
#> Z[4,2] -0.4 -0.2 -0.1 -0.2 0.1 1.05 8 13
#> log_lik[1] -1.0 -1.0 -0.9 -1.0 0.0 2.13 4 13
#> log_lik[2] -2.5 -2.2 -2.1 -2.2 0.1 1.20 5 13
#> log_lik[3] -1.9 -1.6 -1.5 -1.7 0.1 0.95 8 6
#> log_lik[4] -1.2 -1.1 -1.0 -1.1 0.1 1.18 9 13
#> log_lik[5] -0.8 -0.8 -0.8 -0.8 0.0 2.12 4 13
#> log_lik[6] -1.5 -1.2 -1.1 -1.2 0.1 1.20 5 13
#> log_lik[7] -1.0 -0.9 -0.8 -0.9 0.1 0.95 10 6
#> log_lik[8] -1.0 -0.9 -0.8 -0.9 0.1 1.65 9 6
#> log_lik[9] -1.0 -0.9 -0.9 -0.9 0.1 1.60 4 13
#> log_lik[10] -2.2 -2.0 -1.9 -2.0 0.1 0.92 13 13
#> log_lik[11] -1.6 -1.1 -1.0 -1.2 0.2 0.91 13 13
#> log_lik[12] -0.9 -0.9 -0.8 -0.9 0.0 0.93 13 13
#> log_lik[13] -1.6 -1.5 -1.2 -1.5 0.1 1.60 4 13
#> log_lik[14] -1.6 -1.5 -1.3 -1.5 0.1 1.39 5 13
#> log_lik[15] -1.9 -1.4 -1.2 -1.5 0.3 0.96 11 13
#> log_lik[16] -1.8 -1.2 -1.1 -1.3 0.3 1.16 9 6
#> log_lik[17] -1.0 -0.9 -0.9 -1.0 0.1 1.62 4 13
#> log_lik[18] -0.9 -0.9 -0.8 -0.9 0.0 1.63 12 13
#> log_lik[19] -1.5 -0.9 -0.8 -1.0 0.3 0.96 11 13
#> log_lik[20] -1.8 -1.0 -0.8 -1.1 0.4 1.35 9 6
#> log_lik[21] -0.9 -0.9 -0.8 -0.9 0.0 1.60 4 13
#> log_lik[22] -2.0 -1.3 -1.0 -1.3 0.4 1.26 5 13
#> log_lik[23] -1.2 -1.0 -0.8 -1.0 0.1 0.95 10 13
#> log_lik[24] -0.9 -0.8 -0.8 -0.8 0.0 1.02 9 4
#> log_lik[25] -1.7 -1.6 -1.2 -1.6 0.2 1.60 4 13
#> log_lik[26] -2.3 -2.1 -1.6 -2.1 0.2 1.19 7 13
#> log_lik[27] -2.8 -1.8 -1.5 -2.0 0.4 0.96 11 13
#> log_lik[28] -1.0 -0.8 -0.8 -0.9 0.1 1.35 4 13
#> log_lik[29] -1.2 -1.1 -1.0 -1.1 0.1 1.60 4 13
#> log_lik[30] -1.9 -1.7 -1.6 -1.7 0.1 1.49 13 13
#> log_lik[31] -2.7 -1.8 -1.5 -1.9 0.4 0.91 13 13
#> log_lik[32] -1.4 -0.8 -0.8 -1.0 0.2 1.35 7 13
#> log_lik[33] -1.2 -1.1 -0.9 -1.1 0.1 1.60 4 13
#> log_lik[34] -1.2 -0.9 -0.8 -0.9 0.1 1.20 6 13
#> log_lik[35] -1.1 -0.9 -0.8 -0.9 0.1 1.50 10 6
#> log_lik[36] -1.3 -0.9 -0.8 -1.0 0.2 1.35 9 6
#> log_lik[37] -1.1 -0.8 -0.8 -0.9 0.1 2.13 4 13
#> log_lik[38] -0.9 -0.9 -0.8 -0.9 0.0 1.01 13 13
#> log_lik[39] -1.9 -1.5 -0.9 -1.4 0.3 0.91 13 13
#> log_lik[40] -1.4 -1.2 -0.8 -1.1 0.2 1.16 11 13
#> log_lik[41] -2.3 -1.7 -1.6 -1.8 0.3 1.60 4 13
#> log_lik[42] -0.9 -0.8 -0.8 -0.9 0.0 1.79 12 13
#> log_lik[43] -1.2 -1.0 -0.8 -0.9 0.1 1.26 13 6
#> log_lik[44] -1.5 -1.2 -0.8 -1.2 0.3 1.06 9 13
#> log_lik[45] -1.0 -0.9 -0.9 -0.9 0.0 2.13 4 13
#> log_lik[46] -0.9 -0.9 -0.8 -0.9 0.0 1.20 5 13
#> log_lik[47] -1.5 -1.2 -1.0 -1.2 0.1 0.95 10 6
#> log_lik[48] -1.5 -1.3 -1.1 -1.3 0.2 1.18 9 13
#> log_lik[49] -2.2 -1.7 -1.5 -1.8 0.3 1.60 4 13
#> log_lik[50] -1.1 -0.9 -0.8 -1.0 0.1 1.27 5 13
#> log_lik[51] -1.5 -1.1 -0.8 -1.1 0.3 0.93 13 13
#> log_lik[52] -1.1 -1.1 -0.8 -1.0 0.1 1.16 5 4
#> log_lik[53] -1.8 -1.2 -1.0 -1.3 0.4 1.60 4 13
#> log_lik[54] -2.5 -1.8 -1.6 -1.9 0.3 1.39 5 6
#> log_lik[55] -3.3 -2.5 -1.3 -2.3 0.6 0.95 11 6
#> log_lik[56] -1.6 -1.2 -0.8 -1.2 0.3 1.06 11 13
#> log_lik[57] -0.9 -0.8 -0.8 -0.8 0.0 1.18 13 13
#> log_lik[58] -1.1 -0.9 -0.8 -0.9 0.1 1.27 5 13
#> log_lik[59] -1.1 -0.8 -0.8 -0.9 0.1 1.16 5 13
#> log_lik[60] -1.1 -0.9 -0.8 -0.9 0.1 2.11 4 13
#> log_lik[61] -1.3 -1.3 -1.3 -1.3 0.0 1.18 9 13
#> log_lik[62] -1.9 -1.3 -0.8 -1.4 0.4 1.50 4 13
#> log_lik[63] -1.4 -0.9 -0.8 -1.0 0.3 1.18 12 13
#> log_lik[64] -0.9 -0.8 -0.8 -0.9 0.0 1.41 7 4
#> log_lik[65] -0.8 -0.8 -0.8 -0.8 0.0 1.04 10 13
#> log_lik[66] -2.0 -1.6 -1.1 -1.6 0.3 1.26 5 13
#> log_lik[67] -0.9 -0.8 -0.8 -0.8 0.0 1.01 12 13
#> log_lik[68] -2.1 -1.8 -1.7 -1.9 0.2 1.48 12 13
#> log_lik[69] -1.7 -1.6 -1.4 -1.6 0.1 2.13 4 13
#> log_lik[70] -1.0 -0.9 -0.9 -0.9 0.0 1.19 7 6
#> log_lik[71] -2.1 -1.8 -1.5 -1.8 0.2 0.95 10 13
#> log_lik[72] -1.3 -1.1 -1.0 -1.1 0.1 1.35 9 6
#> log_lik[73] -3.8 -3.6 -3.6 -3.6 0.1 1.33 5 13
#> log_lik[74] -1.5 -1.2 -1.1 -1.3 0.1 1.26 5 13
#> log_lik[75] -2.4 -2.0 -1.9 -2.1 0.2 0.96 9 6
#> log_lik[76] -3.0 -2.7 -2.7 -2.8 0.1 0.93 11 13
#> log_lik[77] -2.4 -2.4 -2.2 -2.4 0.1 2.13 4 13
#> log_lik[78] -2.9 -2.2 -2.0 -2.3 0.3 1.26 5 13
#> log_lik[79] -1.0 -0.9 -0.8 -0.9 0.1 0.95 10 13
#> log_lik[80] -5.4 -5.2 -4.8 -5.2 0.2 0.93 11 4
#> xstar[1,1] -2.4 -0.6 1.0 -0.6 1.3 1.12 10 13
#> xstar[2,1] -0.3 0.5 1.5 0.5 0.7 1.37 6 13
#> sigma[1] 0.9 0.9 0.9 0.9 0.0 1.50 7 13
#> lp__ -105.9 -102.5 -102.3 -103.5 1.6 1.25 6 6
#>
#> For each parameter, Bulk_ESS and Tail_ESS are crude measures of
#> effective sample size for bulk and tail quantities respectively (an ESS > 100
#> per chain is considered good), and Rhat is the potential scale reduction
#> factor on rank normalized split chains (at convergence, Rhat <= 1.05).
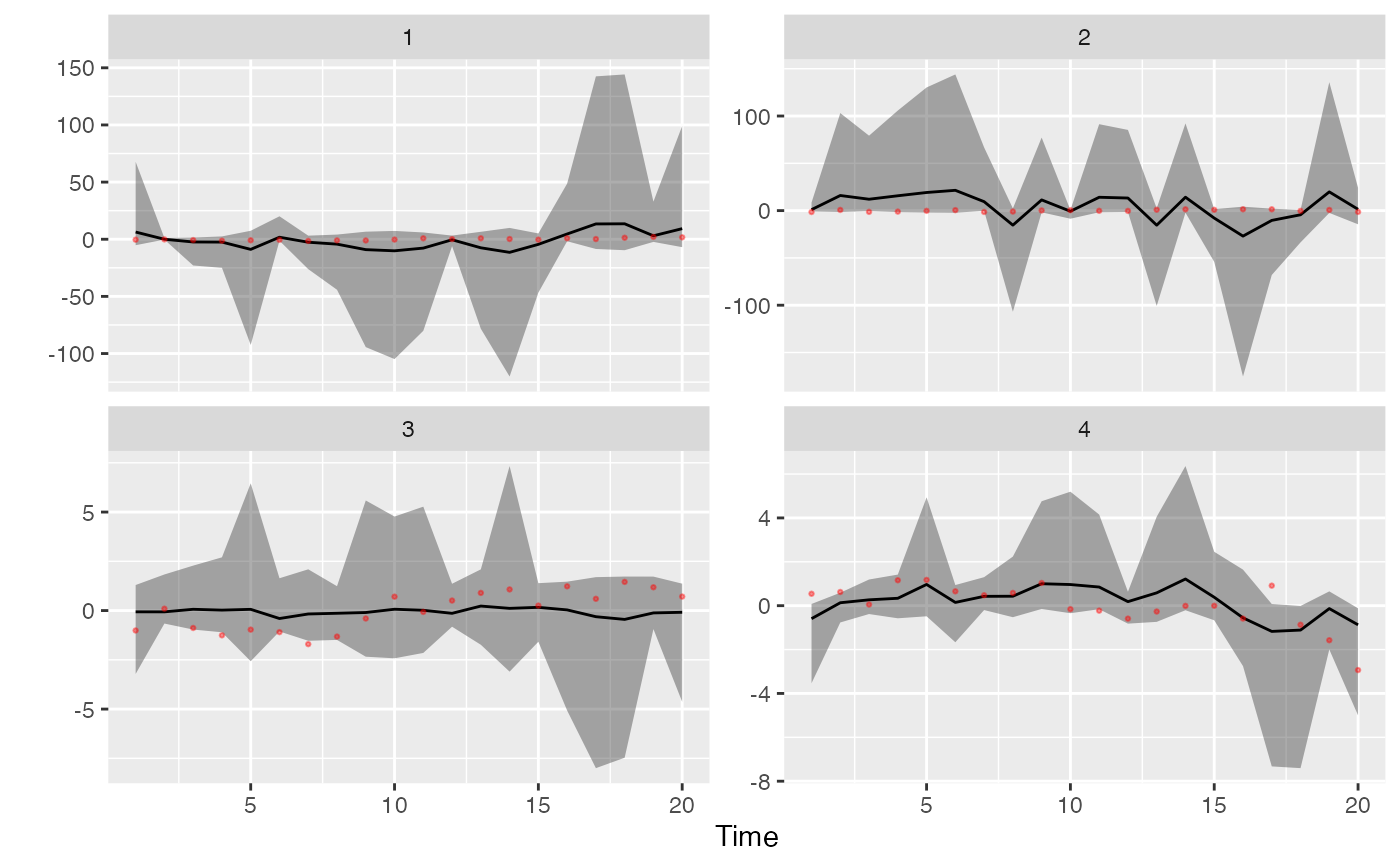
p <- plot_fitted(m)
print(p)
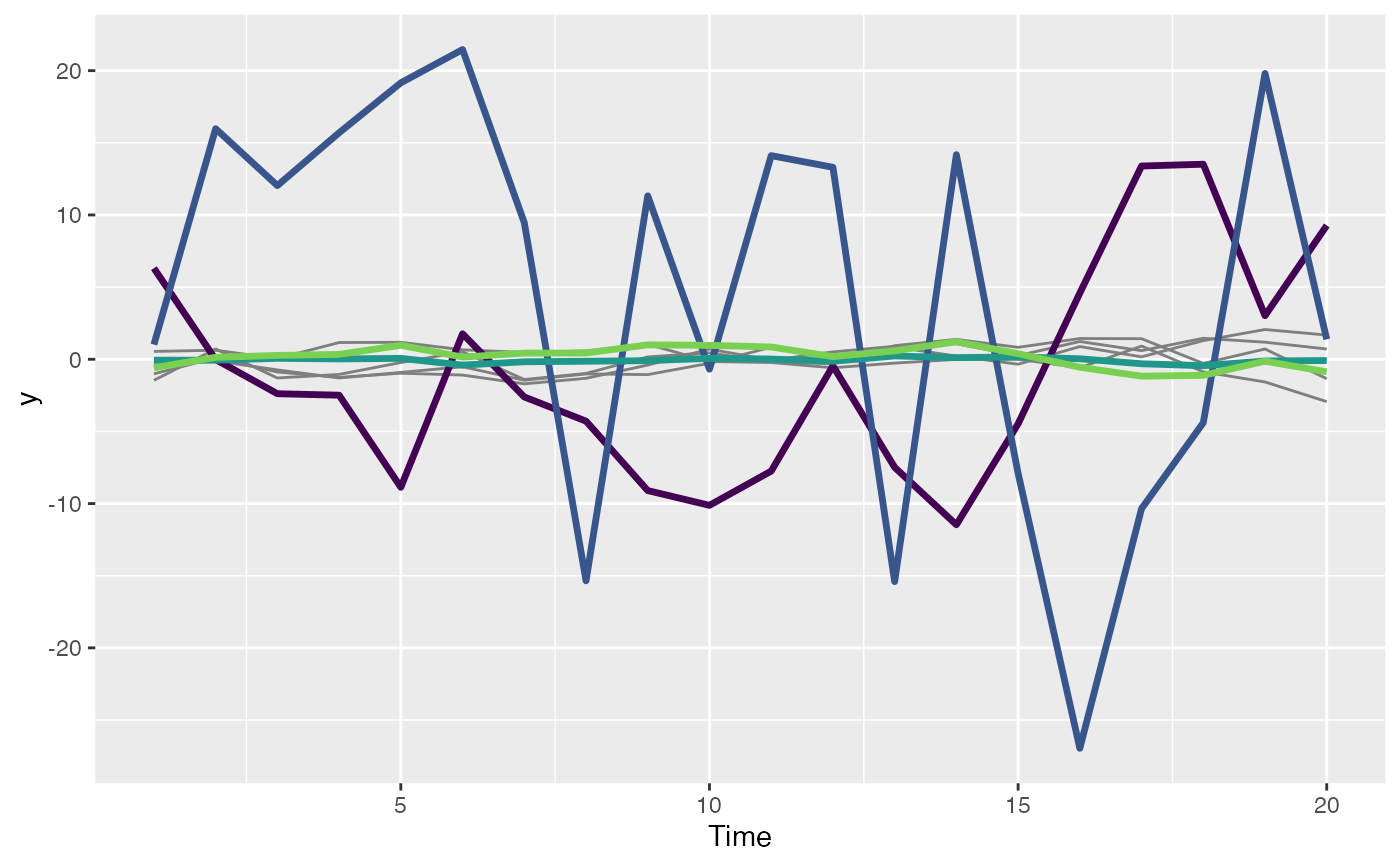
 p <- plot_fitted(m, spaghetti = TRUE)
#> Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
#> ℹ Please use `linewidth` instead.
#> ℹ The deprecated feature was likely used in the bayesdfa package.
#> Please report the issue at <https://github.com/fate-ewi/bayesdfa/issues>.
print(p)
p <- plot_fitted(m, spaghetti = TRUE)
#> Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
#> ℹ Please use `linewidth` instead.
#> ℹ The deprecated feature was likely used in the bayesdfa package.
#> Please report the issue at <https://github.com/fate-ewi/bayesdfa/issues>.
print(p)
 # }
# }